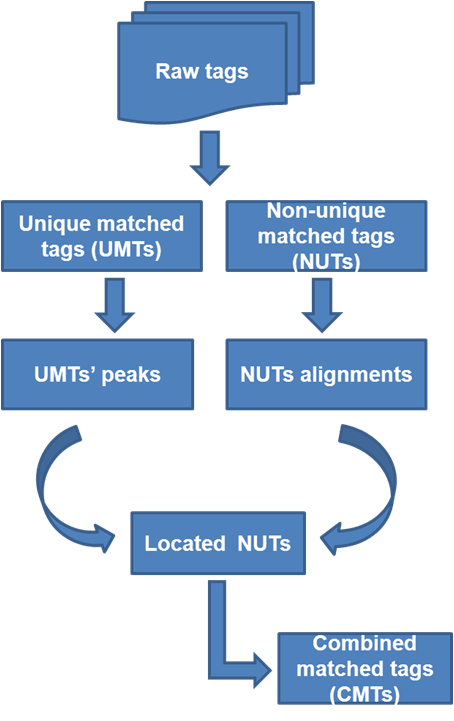
Despite the large number of computational tools that have been developed to analyze ChIP-seq, one big limitation is that most of the existing tools ignore non-unique matched tags (NUTs), including multiple matched tags (MMTs) and no matched tags (NMTs), and merely focus on unique matched tags (UMTs). However, NUTs comprise up to 60% of all raw tags in ChIP-seq data. Effectively utilizing these NUTs would increase the sequencing depth of each sample and allow a more accurate detection of enriched binding sites and target genes, which in turn could lead to more precise and significant biological interpretations. In this study, we have developed a computational tool, LOcating Non-Unique matched Tags (LONUT), which can improve the detection of enriched regions from ChIP-seq. Our LONUT algorithm applies a linear and polynomial regression model to establish an empirical score (ES) formula by considering two influential factors, the distance of NUTs to peaks identified using UMTs and the enrichment score for those peaks. Using this analysis, each NUT is assigned to a unique location on the reference genome. Then, the newly located tags from the set of NUTs are combined with the original UMTs to produce a final set of combined matched tags (CMTs). LONUT was tested on 17 different datasets representing third different characteristics of biological data types. The detected enriched regions were validated using de novo motif discovery, and ChIP-qPCR. We demonstrate the sufficiency, specificity and accuracy of LONUT and show that our program not only improves the detection of enriched regions (binding sites for ChIP-seq), but also identifies additional enriched regions from the sequencing data.